Chapter Nine
Images, Narrative, and Gestures for Explanation
Most of this book up to this point has been about how to display data for the data analyst. It has been about data exploration and how to present data so that new things can be discovered. But there is another major use of visualization, and that is the explanation of patterns in data. Once something has been understood by someone, that person must usually present those results to other people, with the goal of convincing them that one interpretation or another is correct. The cognitive processes involved (i.e., interpreting data and explaining data) are very different.
One way of elucidating this difference is to think about who or what is in control of the cognitive sequence. The process of visual thinking can be thought of as a kind of collaborative dialogue between a person and a visual representation, especially if the visualization is computer based and interactive. In the case of data exploration, the cognitive processes of the data analyst are in control. Conversely, in the case of the presentation of results, it is the presenter, the author of an article, or the designer of a poster who is, or should be, in control of the cognitive thread (Ware, 2009). The audience takes in a series of visual patterns and words in a sequence that is controlled by the presenter. This material will occupy most of the capacity of both visual and verbal working memories, and any attention controlling sequence of information is a form of narrative. In this chapter, we will explore the different ways that images and words can be used to create narrative structure.
We will address the problem of integrating visual and verbal materials in multimedia presentations. We will also address the particularly thorny but interesting problem of whether or not we should be using visual languages to program computers. Although computers are rapidly becoming common in every household, very few people are programmers, and it has been suggested that visual programming languages may make it easier for “nonprogrammers” to program computers.
The Nature of Language
Before going on to consider whether or not we can or should have such a thing as a visual language, we need to think about the nature of language. Noam Chomsky revolutionized the study of natural language because he showed that there are aspects of the syntactic structure of language that generalize across cultures (Chomsky, 1965). A central theme of his work is the concept that there are “deep structures” of language, representing innate cognitive abilities based on inherited neural structures. In many ways, this work forms the basis of modern linguistics. The fact that Chomsky’s analysis of language is also a cornerstone of the theory of computer languages lends support to the idea that natural languages and computer languages have the same cognitive basis.
Other evidence supports the innateness theory. There is a critical period for normal language development that extends to about age 10; however, language is most easily acquired in the interval from birth to age 3 or 4. If we do not obtain fluency in some language in our early years, we will never become fluent in any language. Also, there are areas in the brain specialized for spoken language production (Broca’s area) and language comprehension (Wernicke’s area). These are distinct from the areas associated with visual processing, suggesting that language processing, whatever it is, is distinct from visual processing.
Sign Language
Despite the evidence for special brain areas, being verbal is not a defining characteristic of natural language capacity. Sign languages are interesting because they are examples of true visual languages. If we do not acquire sign languages early in life, we will never become very adept at using them. Sign languages are not translations of spoken languages, but are independent, having their own grammars. Groups of deaf children spontaneously develop rich sign languages that have the same deep structures and grammatical patterns as spoken language. These languages are as syntactically rich and expressive as spoken language (Goldin-Meadow & Mylander, 1998).
Sign languages grew out of the communities of deaf children and adults that were established in the 19th century, arising spontaneously from the interactions of deaf children with one another. Sign languages are so robust that they thrived despite efforts of well-meaning teachers to suppress them in favor of lip reading—a far more limiting channel of communication. There are many sign languages; British sign language is a radically different language from American sign language, and the sign language of France is similarly different from the sign language of francophone Quebec (Armstrong et al., 1994).
Although in spoken languages words do not resemble the things they reference (with a few rare exceptions), signs are partially based on similarity; for example, see the signs for a tree illustrated in Figure 9.1. Sign languages have evolved rapidly. The pattern appears to be that a sign is originally created on the basis of a form of similarity in the shape and motion of the gesture, but over time the sign becomes more abstract and similarity becomes less and less important (Deuchar, 1990). It is also the case that even signs apparently based on similarity are only recognized correctly about 10% of the time without instruction, and many signs are fully abstract.

Figure 9.1 Three different sign language representations of a tree. Note that they are all very different and all incorporate motion. From Bellugi & Klima (1976). Reproduced with permission.
Even though sign language is understood visually and produced through hand gestures, the same brain areas are involved in comprehension and production as are involved in speech comprehensions and production (Emmorey & McCullough, 2009). This tells us that language has distinct brain subsystems that function in the same roles, no matter what the sensory input or means of production.
Language is Dynamic and Distributed over Time
We take in spoken, written, and sign language serially; it can take a few seconds to hear or read a short sentence. Armstrong et al. (1994) argued that, in important ways, spoken language is essentially dynamic. Verbal expression does not consist of a set of fixed, discrete sounds; it is more accurately described as a set of vocal gestures producing dynamically changing sound patterns. The hand gestures of sign language are also dynamic, even when denoting static objects, as Figure 9.1 illustrates. There is a dynamic and inherently temporal phrasing at the syntactic level in the sequential structure of nouns and verbs. Also, written language, although it comes in initially through the visual channel, is transformed into a sequence of mentally recreated dynamic utterances when it is read. In contrast with the dynamic, temporally ordered nature of language, relatively large sections of static pictures and diagrams can be understood in parallel. We can comprehend the gist of a complex visual structure in a fraction of a second, based on a single glance.
Is Visual Programming a Good Idea?
The difficulty of writing and understanding computer programs has led to the development of a number of so-called visual languages in the hope that these can make the task easier; however, we must be very careful in discussing these as languages. Visual programming languages are mostly static diagramming systems, so different from spoken languages that using the term language for both can be more misleading than helpful. There is a case to be made that computer programming languages have more in common with natural language processing than with visual processing, and that for this reason, programming is better done using methods that relate more closely to natural language.
Consider the following instructions that might be given to a mailroom clerk:
This is very like the following short program, which beginning programmers are often asked to write:
Repeat
get a line of text from the input file
change all the lowercase letters to uppercase
write the line to the output file
Until (there is no more input)
This example program can also be expressed in the form of a diagram called a flowchart (see Figure 9.2).
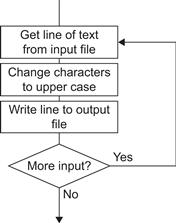
Figure 9.2 A flowchart is often a poor way to represent information that can be readily expressed in natural language-like pseudocode.
Flowcharts provide a salutary lesson to those who design visual programming languages. Flowcharts were once part of every introductory programming text, and it was often a contractual requirement that large bodies of software be documented with flowcharts describing the code structure. Once almost universally applied, flowcharts are now almost defunct. Why did flowcharts fail? It seems reasonable to attribute this to a lack of commonality with natural language.
Written and spoken languages, as well as sign languages, are packed with words such as if, else, not, while, but, maybe, perhaps, probably, and unlikely. These provide external manifestations of the logical structure of human thought (Pinker, 2007). We learn the skills of communication and refine our thinking skills early in life when we learn to talk. Using natural language-like pseudocode transfers these skills we already have gained in expressing logic through natural language.
A graphical flowchart representing the same program must be translated before it can be interpreted in the natural language processing centers. If, as infants, we learned to communicate by drawing diagrams on paper and if society had developed a structured language for this purpose, then visual programming would make sense, but this is not the case.
Nevertheless, some types of information are much better described in the form of diagrams. A second example illustrates this. Suppose that we wish to express a set of propositions about the management hierarchy of a small company.
This pattern of relationships is far more clearly expressed in a diagram, as shown in Figure 9.3. These two examples suggest that visual language, in the form of static diagrams, has certain expressive capabilities that are very different from, and perhaps complementary to, natural language. Diagrams should be used to express structural relationships among program elements, whereas words should be used to express detailed procedural logic.
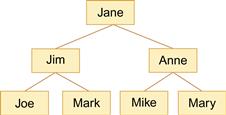
Figure 9.3 A simple organization chart showing the management structure.
Throughout this book it has been argued that the strength of visualization is that the perceptual representation of certain types of information can be easily understood. Logical constructs do not appear to constitute one of the types of information for which a natural visual representation exists. Also, although the existence of sign languages suggests that there can be visual analogs to natural language, the principle of arbitrariness still applies, so there is no advantage to this form or representation. On balance, the evidence suggests that the detailed logic of programming is best done using methods that rely on words more than graphical codes. Accordingly, we propose the following two broad principles:
[G9.1] Use methods based on natural language (as opposed to visual pattern perception) to express detailed program logic.
[G9.2] Graphical elements, rather than words, should be used to show structural relationships, such as links between entities and groups of entities.
None of the above should be taken as an attack on visual programming environments, such as Microsoft® Visual Basic® or Borland’s Delphi, but it is worth noting that these are hybrids, as they are far from purely visual. They have many words in their user interfaces, and the way in which programming is done is mixed; some operations are done by connecting boxes, but others require text entry.
Images versus Sentences and Paragraphs
The greatest advantage of words over images and diagrams, either static or dynamic, is that spoken and written natural language is ubiquitous. It is by far the most elaborate, complete, and widely shared system of symbols that we have available. For this reason alone, it is only when there is a clear advantage that visual techniques are preferred. That said, images have clear advantages for certain kinds of information, and a combination of images and words will often be best. A visualization designer has the task of deciding whether to represent information visually, using words, or both. Other, related choices involve the selection of static or moving images and spoken or written text. If both words and images are used, methods for linking them must be selected. Useful reviews of cognitive studies that bear on these issues have been summarized and applied to multimedia design by a number of authors, including Strothotte and Strothotte (1997), Najjar (1998), and Faraday (1998). What follows is a summary of some of the key findings, beginning with the issue of when to use images vs. words separately and in combination.
We have been discussing the special case of programming languages, but the same principles apply in general to the question of whether to display information graphically or with text. Text is better than graphics for conveying abstract concepts (Najjar, 1998), and procedural information is best provided using text or spoken language, or sometimes text integrated with images (Chandler & Sweller, 1991).
We can begin by proposing a more general version of guideline G9.1.
[G9.3] Use methods based on natural language (as opposed to visual pattern perception) to represent abstract concepts.
Of course, it is important that the information be well presented, no matter what the medium. Visual information must be meaningful and capable of incorporation into a cognitive framework for a visual advantage to be realized (Bower et al., 1975).
There are also design considerations relating to the viewing time for images. It takes time to scan a complex diagram for its details. Only a little information is extracted in the first glance. A number of studies support the idea that we first comprehend the shape and overall structure of an object, and then we comprehend the details (Price & Humphreys, 1989; Venturino & Gagnon, 1992). Because of this, simple line drawings may be most effective for quick exposures.
Links between Images and Words
The central claim of multimedia theory is that providing information in more than one medium of communication will lead to better understanding (Mousavi et al., 1995). Mayer et al. (1999) and others have translated this into a theory based on dual coding. They suggest that if active processing of related material takes place in both visual and verbal cognitive subsystems, learning will be better. It is claimed that duplicate coding of information in more than one modality will be more effective than single-modality coding. The theory also holds that it is not sufficient for material to be simply presented and passively absorbed; it is critical that both visual and verbal representation be actively constructed, together with the connections between them.
Supporting multimedia theory, studies have shown that images and words in combination are often more effective than either in isolation (Wadill & McDaniel, 1992; Faraday & Sutcliffe, 1997). Faraday and Sutcliffe (1997) found that propositions given with a combination of imagery and speech were recalled better than propositions given only through images. Faraday and Sutcliffe (1999) showed that multimedia documents with frequent and explicit links between text and images can lead to better comprehension. Fach and Strothotte (1994) theorized that using graphical connecting devices between text and imagery can explicitly form cross-links between visual and verbal associative memory structures. Care should be taken in linking words and images. For obvious reasons, it is important that words be associated with the appropriate images. These links between the two kinds of information can be static, as in the case of text and diagrams, or dynamic, as in the case of animations and spoken words. There can be a two-way synergy between text and images.
Despite these studies, there is little or no support for the claim that providing information in both images and words is better than providing information in either medium. None of the early studies actually presented the same information in both media (Mayer et al., 2005). Showing a picture of a pile containing apples, oranges, and bananas is not the same as showing the word fruit. But, there is a considerable advantage in choosing the most appropriate kind of representation for elements of a data set, and often this will involve a mixed-media representation; some information is best represented using words, whereas other information is best represented using lines, textures, and colored regions. Of course, it is essential that different types of representation be clearly and effectively linked. A much better multimedia principle is the following:
[G9.4] To represent complex information, separate out components according to which medium is most efficient for each display—that is, images, moving or static, or words, written or spoken. Present each kind of information accordingly. Use the most cognitively efficient linking techniques to integrate the different kinds of information.
We now turn our attention to efficient linking methods.
Integrating Visual and Verbal and the Narrative Thread
In a textbook, written words must be linked with static diagrams, whereas in a lecture written words, spoken words, static images, and moving images are all choices.
Linking Text with Graphical Elements of Diagrams
Beyond merely attaching text labels to parts of diagrams, there is the possibility of integrating more complex procedural information. Chandler and Sweller (1991) showed that instructional procedures for testing an electrical system were understood better if blocks of text were integrated with the diagram, as shown in Figure 9.4. In this way, process steps could be read immediately adjacent to the relevant visual information. Sweller et al. (1990) used the concept of limited-capacity working memory to explain these and similar results. They argued that when the information is integrated there is a reduced need to store information temporarily while switching back and forth between locations.
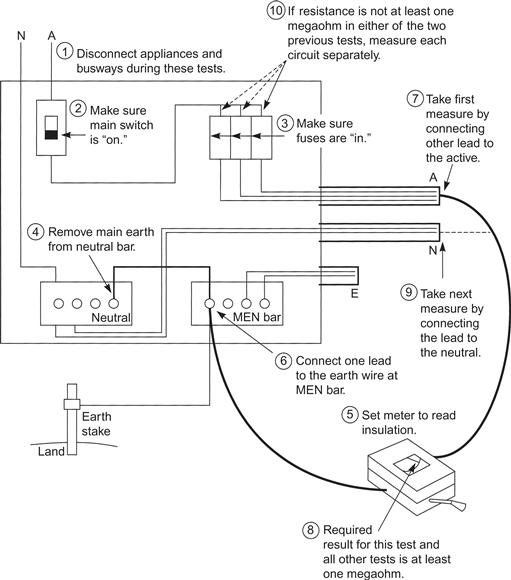
Figure 9.4 An illustration used in a study by Chandler and Sweller (1991). A sequence of short paragraphs is integrated with the diagram to show how to conduct an electrical testing procedure. Reprinted with permission.
[G9.5] Place explanatory text as close as possible to the related parts of a diagram, and use a graphical linking method.
At this point, it is worth commenting that the above guideline is not followed in most textbooks, and the one you are reading is no exception. This is because of the constraints of the publishing industry. Textbook layout is completely out of the hands of the author, making it extremely difficult to carefully integrate the words and graphics (Ware, 2008). As a result, text and figures are frequently separated by a few pages, leading to inevitable decline in cognitive efficiency.
Gestures as Linking Devices in Verbal Presentations
Someone giving a talk has the choice of putting the words on the screen or speaking them. If words are on the screen, however, the presenter loses control of the cognitive thread. Audience members will inevitably read ahead, and usually what they are thinking about will not correspond well to what the speaker is saying or to the parts of the images the speaker is pointing at. In addition, there is a clear cognitive efficiency to verbal presentation (as opposed to text) combined with images. Someone cannot read and look at part of a diagram at the same time, but they can listen to verbal information and look at part of a diagram simultaneously (Mousavi et al., 1995).
[G9.6] When making presentations, spoken information, rather than text information, should accompany images.
Deixis
The act of indicating something by pointing is called a deictic gesture in human communication theory. Often such a gesture is combined with speech so that it links the subject of a spoken sentence with a visual reference. When people engage in conversation, they sometimes indicate the subject or object in a sentence by pointing with a finger, glancing, or nodding in a particular direction. For example, a shopper might say, “Give me that one,” while pointing at a particular wedge of cheese at a delicatessen counter.
The deictic gesture is considered to be the most elementary of linguistic acts. A child can point to something desirable, usually long before she can ask for it verbally, and even adults frequently point to things they wish to be given without uttering a word. Deixis can be accomplished with a glance, a nod of the head, or a change in body orientation. It can be enhanced by using a tool, such as a straight rod. Deixis has its own rich vocabulary; for example, an encircling gesture can indicate an entire group of objects or a region of space (Levelt et al., 1985; Oviatt et al., 1997), and a flutter of the hand may add uncertainty to the bounded region.
To give a name to a visual object, we often point and speak its name. Teachers will talk through a diagram, making a series of linking deictic gestures. To explain a diagram of the respiratory system, a teacher might say, “This tube connecting the larynx to the bronchial pathways in the lungs is called the trachea,” with a gesture toward each of the important parts.
Deictic techniques can be used to bridge the gap between visual imagery and spoken language. Some shared computer environments are designed to allow people at remote locations to work together while developing documents and drawings. Gutwin et al. (1996) observed that, in these systems, voice communication and shared cursors are the critical components in maintaining dialogue. Transmitting an image of the person speaking is usually much less valuable. Another major advantage of combining gestures with visual media is that this multimodal communication results in fewer misunderstandings (Oviatt et al., 1997; Oviatt, 1999), especially when English is not the speaker’s native language.
[G9.7] Use some form of deixis, such as pointing with a hand or an arrow, or timely highlighting to link spoken words and images.
Oviatt et al. (1997) showed that, given the opportunity, people like to point and talk at the same time when discussing maps. They studied the ordering of events in a multimodal interface to a mapping system in which a user could both point deictically and speak while instructing another person in a planning task using a shared map. The instructor might say something like “Add a park here” or “Erase this line” while pointing to regions of the map. One of their findings was that pointing generally preceded speech; the instructor would point to something and then talk about it.
[G9.8] If spoken words are to be integrated with visual information, the relevant part of the visualization should be highlighted just before the start of the accompanying speech segment.
Web-based presentation enables a form of deixis with textual material. Links can be made by mouse clicks. In a study of eye movements, Faraday and Sutcliffe (1999) found that people would read a sentence, then look for the reference in an accompanying diagram. Based on this finding, they created a method for making it easy for users to make the appropriate connections. A button at the end of each sentence caused the relevant part of the image to be highlighted or animated in some way, thus enabling readers to switch attention rapidly to the correct part of the diagram. They showed that this did indeed result in greater understanding.
Symbolic Gestures
In everyday life, we use a variety of gestures that have symbolic meaning. A raised hand signals that someone should stop moving or talking. A wave of the hand signals farewell or hello. Some symbolic gestures can be descriptive of actions; for example, we might rotate a hand to communicate to someone that they should turn an object. McNeill (1992) called these gestures kinetographics. With input devices, such as the DataGlove, that capture the shape of a user’s hand, it is possible to program a computer to interpret a user’s hand gestures. This idea has been incorporated into a number of experimental computer interfaces. In a notable study carried out at MIT, researchers explored the powerful combination of hand gestures and speech commands (Thorisson et al., 1992). A person facing the computer screen first asked the system to
This caused a table to appear on the floor in the computer visualization. The next command,
was combined with a gesture placing the fist of one hand on the palm of the other hand to show the relative location of the vase on the table. This caused a vase to appear on top of the table. Next, the command
was combined with a twisting motion of the hand, causing the vase to rotate as described by the hand movement.
Full-body sensing devices, such as the Microsoft® Kinect™, make this approach very affordable. Although the use of such devices outside of the realm of video games is still experimental, combining words with gestures may ultimately result in communication that is more effective and less prone to error (Mayer & Sims, 1994).
Expressive Gestures
Gestures can have an expressive dimension in addition to being deictic. Just as a line can be given a variety of qualities by being made thick, thin, jagged, or smooth, so can a gesture be made expressive (McNeill, 1992; Amaya et al., 1996). A particular kind of hand gesture, called a beat, sometimes accompanies speech, emphasizing critical elements in a narrative. Bull (1990) studied the way political orators use gestures to add emphasis. Vigorous gestures usually occurred at the same time as vocal stress. Also, the presence of both vigorous gestures and vocal stress often resulted in applause from the audience. In the domain of multimedia, animated pointers sometimes accompany spoken narrative, but often quite mechanical movements are used to animate the pointer. Perhaps by making pointers more expressive, critical information can be brought out more effectively.
Animated versus Static Presentations
In the early days of multimedia research, extravagant claims were made for the superiority of animated presentations combined with written or spoke text, compared to static presentation of the information. These claims have not withstood careful analysis. A review of the studies carried out by Tversky et al. (2002) found that the majority failed to show advantages of animated over static presentations. Where they did find a difference, it could be attributed to the lack of equivalence of the information presented dynamically versus statically.
In one of the few studies where care was taken to ensure that the same information was available in both animated and static presentations, Mayer et al. (2005) found that the static version resulted in better retention of the information and better ability to generalize from the materials, indicating a deeper understanding. To present the static information, they used cartoon like series of frames, with each frame illustrating a key concept. Figure 9.5 shows one of the examples they used. In this case, the goal was to explain how a toilet flushing mechanism works.
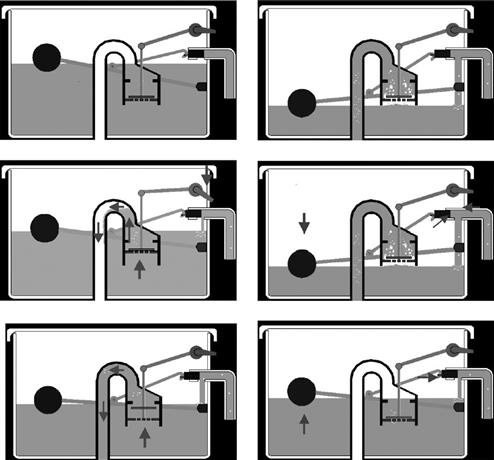
Figure 9.5 One of the explanatory diagrams used in a study by Mayer et al. (2005) to investigate animated versus static diagrams. From Mayer et al. (2005). Reproduced with permission.
KidSim was a visual programming language based on animated characters (Cypher & Smyth, 1995). Rader et al. (1997) carried out an extensive independent evaluation of KidSim in two classrooms over the course of a year. The system was deliberately introduced without explicit teaching of the underlying programming concepts. They found that children rapidly learned the interactions needed to draw animated pictures but failed to gain a deep understanding of the programs. The children often tried to generalize the behavior they saw in ways that the machine did not understand. Students sometimes found it frustrating when they set up conditions they thought should cause some action, with no results.
A study by Palmiter et al. (1991) provided two kinds of instructions for a procedural task; one was an animated demonstration, and the other was a written text. They found that immediately following instruction, the animated demonstration produced better performance, but a week later the results reversed, as those who received written instructions did better. They explained these results by suggesting that in the short term subjects given animated instructions could simply mimic what they had recently seen. In the longer term, the effort of interpreting the written instructions produced a deeper symbolic coding of the information that was better retained over time.
An explanation for the failure to find an advantage for animations can be found in an analysis of the processes involved in constructing meaning. In order to construct a cognitive model explaining a series of events, it is necessary for the learner to construct hypotheses and then test them against the available information. The static diagram may provide better support for this than an animated sequence for a number of reasons. Usually, the key information relating to the hypotheses can be more clearly presented statically, although of course this depends on good design. A static diagram sequence, such as that shown in Figure 9.5, offers access at any time, via eye movements, to the different parts of the explanation, allowing the learner to gain the information at exactly the time it is needed in the process of cognitive model construction (Mayer et al., 2005; Ware, 2009). Also, with static materials, a learner must mentally animate components from one state to the next, and it is precisely this kind of cognitive effort that can promote a deeper understanding (Mayer et al., 2005).
Heiser et al. (2004) offer a set of principles for the design of assembly diagrams, derived from an analysis of the task in cognitive terms (see Figure 9.6). Here they are given as guidelines.
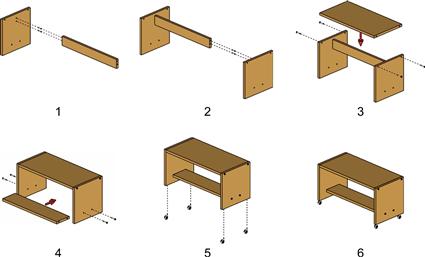
Figure 9.6 An example of an assembly diagram designed according to a set of cognitive best practices developed by Heiser et al. (2004).
[G9.9] Use the following principles when constructing an assembly diagram: (1) A clear sequence of operations should be evident to maintain the narrative sequence. (2) Components should be clearly visible and identifiable. (3) The spatial layout of components should be consistent from one frame to the next. (4) Actions should be illustrated, along with connections between components.
Visual Narrative
Despite the evidence from academic studies, animated visualizations are increasingly developed for television science shows and interactive computer displays. We now turn our attention to how animation may be most effective, while recognizing that research suggests that static representations are likely to be as good as or better than animations.
The silent movies of the 1920s show that narrative can be conveyed visually as well as verbally. This means that the cognitive thread of a viewer can be controlled by getting him to look at particular objects and actions in a particular sequence. When movies are made, it is the job of the director and cinematographer to design sequences of actions and frame camera shots in such a way that viewers are strongly constrained to look at particular objects at particular times, ensuring that their visual working memories will be filled with information in a certain sequence that carries the plot. When the goal is to explain scientific concepts by establishing a sequence of ideas in the minds of an audience, the same techniques may be applied to the visual presentation of information derived from data.
In cinematography, attention is controlled by means of different kinds of camera shots and transitions between them. Establishing shots, zooms, close-ups, and dolly shots, as well as various kinds of transition, are just a few of the commonly applied methods. These are mostly beyond the scope of this book, but only because most of them have not been formally studied by vision scientists; however, anyone wishing to make high-quality science videos would do well to study this craft. Here, we will restrict ourselves to work that has been done by psychologists and researchers working on effective educational visualizations.
Moving the viewpoint in a three-dimensional (3D) visualization can function as a form of narrative control. Obviously, we can only see what is in the camera frame, and large centrally placed objects are more likely to draw attention than peripheral small objects. A virtual camera can be moved from one part of a 3D data space to another, drawing attention to different features. In some complex 3D visualizations, a sequence of shots is spliced together to explain a complex process.
Shot transitions are defined by an instantaneous translation of a camera in space and/or time; the result can be confusion with respect to where and when the viewer feels he is situated. Hochberg and Brooks (1978) developed the concept of visual momentum in trying to understand how cinematographers link different camera shots together so the viewer can relate objects seen in one clip with objects seen in the next. As a starting point, they argued that in normal perception people do not take more than a few glances at a simple static scene; following this, the scene “goes dead” visually. In cinematography, the device of the cut enables the director to create a kind of heightened visual awareness, because a new perspective can be provided every second or so. The problem faced by the director is that of maintaining perceptual continuity. If a car travels out of one side of the frame in one scene, it should arrive in the next scene traveling in the same direction; otherwise, the audience may lose track of it and pay attention to something else.
Hochberg (1986) showed that identification of image detail was better when an establishing shot preceded a detail shot than when the reverse ordering was used. This suggests that an overview map should be provided first when an extended spatial environment is being presented. An option that is available in data visualization is to always display a small overview map. The use of an overview map is common in many adventure video games as well as navigation systems used in aircraft or ground vehicles. Such maps are usually small insets that provide a larger spatial context, supplementing the more detailed local map. The same kind of technique can be used with large information spaces. The general problem of providing focus and context is also discussed in Chapter 10.
In the film industry, people are employed to ensure continuity; this involves making sure that clothing, makeup, and props are consistent from one cut to another. In visualization, Wickens (1992) proposed the principle of using consistent representations—the same kinds of information should be conveyed with the same colors and symbol shapes.
[G9.10] Use consistent representations from one part of a visualization sequence to the next. The same visual mappings of data must be preserved. This includes presenting similar views of 3D objects.
A second device that can be used to allow viewers to cognitively link one view of a data space to the next is what Wickens (1992) called an anchor. Certain visual objects may act as visual reference points, tying one view of a data space to the next. An anchor is a constant, invariant feature of a displayed world. Anchors become reference landmarks in subsequent views. Ideally, when cuts are made from one view to another, several anchors should be visible from the previous frame. One common kind of frame used in visualization are axis marks that show some kind of scale information. A third method for maintaining visual continuity is the idea of an overview map. This is also discussed in the next chapter.
[G9.11] Use graphic devices, such as frames and landmark objects, to help maintain visual continuity from one view of a data space to another.
Animated Images
Despite the evidence that static representations are at least as good as animated representations, researchers have continued to investigate ways that dynamic representations can be made more effective. The problem with animations is that only a short segment is likely to be applicable to a viewer’s cognitive modeling processes at any instant. If the sequence is long, much time is wasted replaying it just to get the bit that is currently relevant. One technique designed to help with this is to break explanatory animations into short segments. Each section can be viewed when the user is mentally prepared to engage with that particular aspect of the cognitive task. If it is short, it can easily be replayed multiple times.
In a study of an instructional animation explaining the causes of day and night (based on rotation of the Earth), Hasler et al. (2007) compared three modes of presentation. In the first, the animation was run straight through, although it could be replayed. In the second, stop and start buttons allowed the user to pause and resume play at any time. In the third, the animation was broken into a series of segments, each of which could be independently played. The results showed that both of the interactive modes produced higher test performance with lower cognitive load scores.
[G9.12] Animated instructions should be broken into short meaningful segments. Users should be given a method for playing each segment independently.
It also seems plausible that animation can represent basic concepts in a way that is not possible in static diagrams. The work of researchers such as Michotte (1963), Heider and Simmel (1944), and Rimé et al. (1985), discussed in Chapter 6, shows that people can perceive events such as hitting, pushing, and aggression when geometric shapes are moved in simple ways. None of these things can be expressed with any directness using a static representation, although many of them can be expressed well using words. Animation brings graphics closer to words in expressive capacity.
Possibly the single greatest enhancement of a diagram that can be provided by animation is the ability to express causality (Michotte, 1963). With a static diagram, it is possible to use some device, such as an arrow, to denote a causal relationship between two entities, but the arrowhead is a conventional device that perceptually shows that there is some relationship, necessarily causality. The work of Michotte shows that with appropriate animation and timing of events, a causal relationship will be directly and unequivocally perceived.
A final point about animation is that certain visualizations are intended to teach people to perform physical movements—for example, teaching someone a tennis stroke. There is increasing evidence that the brain contains mirror neurons. These are cells that respond directly to the actions of others, and they facilitate the perceiver performing those exact same motions (Rizzolatti & Sinigaglia, 2008). This suggests that a clear advantage should be obtained in teaching movements using animation, as opposed to a series of static stills. Based on a study of mechanical troubleshooting, Booher (1975) concluded that an animated description is the best way to convey perceptual motor tasks, but verbal instruction is useful to qualify the information.
[G9.13] Use animation of human figures to teach people how to make specific body movements by imitation.
It is also likely that mirror neurons can be the medium for motivating learners. If our brains mirror an enthusiastic person, this may make us more enthusiastic (see Figure 9.7). Certainly, energetic, exaggerated body gestures are common to many motivational speakers.

Figure 9.7 Mirror neurons may be the medium whereby one person motivates another. From http://www.honeysquad.com/index.php/tag/add-new-tag/. With permission.
Conclusion
Most complex visualizations used in explanations are hybrids of visual and verbal material. The message of this chapter is that information should be displayed in the most appropriate medium. Also, to obtain a positive benefit from multimedia presentations, cross-references must be made so that the words and images can be integrated conceptually. Both time and space can be used to create these cross-links. The deictic gesture, wherein someone points at an object while speaking about it, is probably the most elementary of visual–verbal linking devices. It is deeply embedded in human discourse and provides the cognitive foundation for other linking devices.